

Why we still use Doxygen (just not the way you think)
Doxygen isn't dead. The default output is. Here's how we turn it into docs users actually read.

Last month at a Write the Docs Barcelona meetup, someone asked me: “Do you see tools like Doxygen going out of style?”
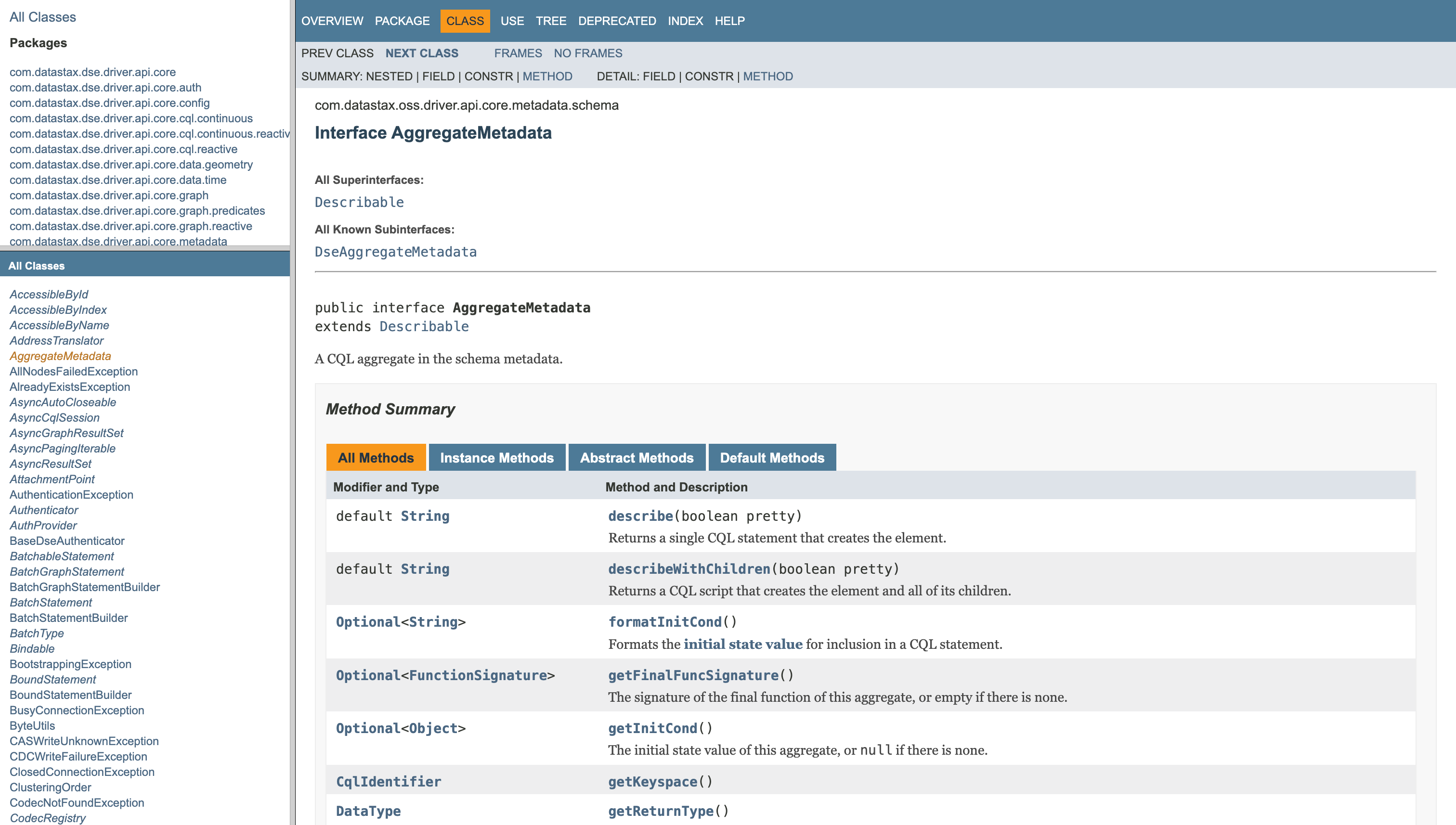
It’s a fair question. Doxygen’s default output looks vintage, and most people who land on it don’t stick around.
The problem isn’t Doxygen
Doxygen is great at the part most people don’t want to do themselves: parsing code comments and extracting structured information. Class hierarchies, function signatures, parameter descriptions, return types, defaults.
The problem is what comes out of the box. The HTML looks like it was built two decades ago, and it lives as a separate site with its own search, disconnected from the docs users already know. It feels like a different product altogether.
So engineers close the tab. Writers stop pushing for it. The reference docs either don’t get published, or they get published and nobody reads them. Neither is good.
Use Doxygen as a parser, not a publisher
Doxygen also generates XML alongside HTML. Same structured data, in a format you can actually work with.
From that XML you can produce markdown, RST, or whatever format your docs platform expects. The API reference becomes part of your docs instead of a separate site bolted on. Sphinx, Docusaurus, Antora, MkDocs, whatever you’re already using.
We did this for ScyllaDB’s Driver docs. Built a custom extension that consumed the Doxygen XML and rendered it as native Sphinx pages.
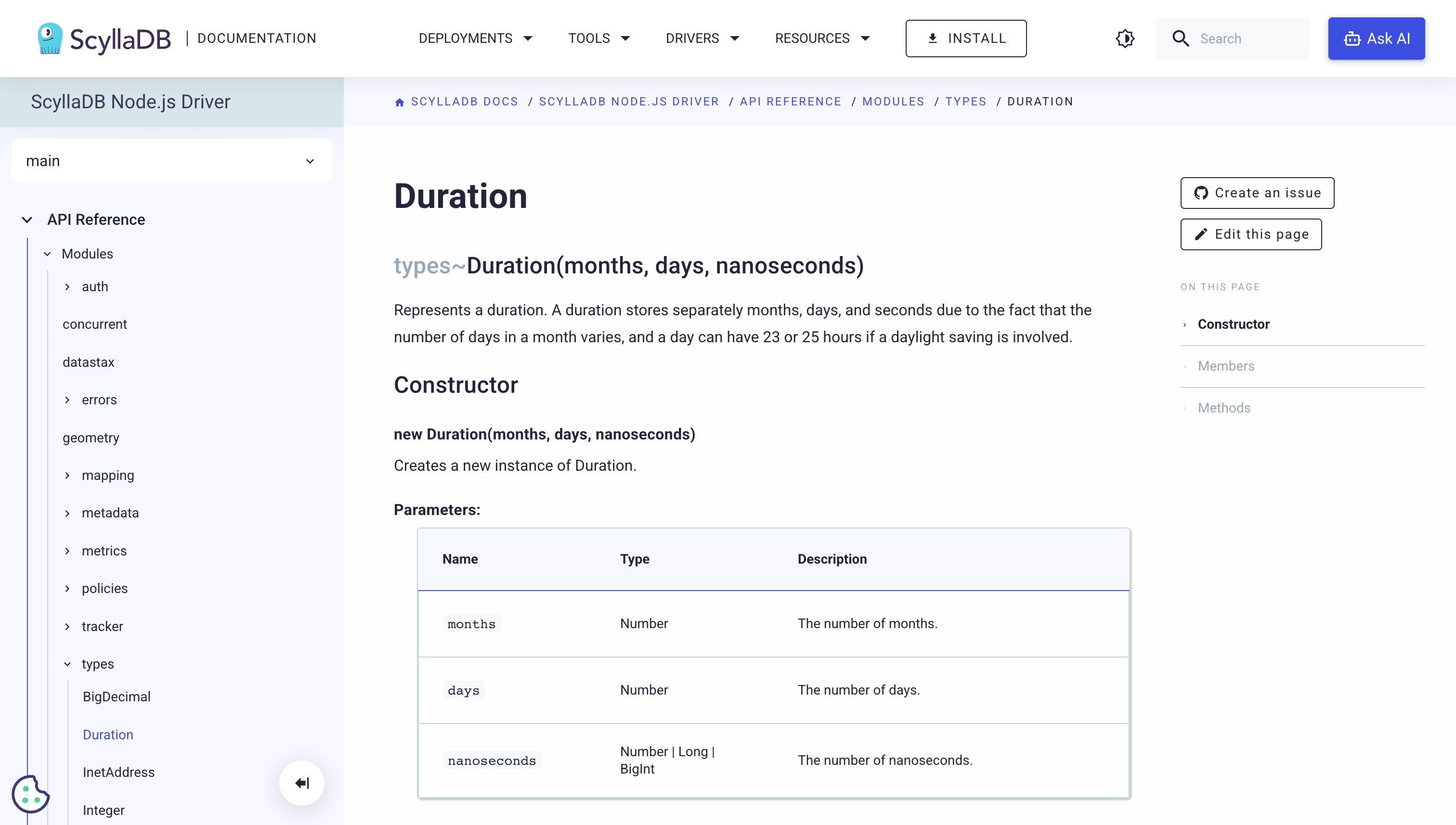
The API reference now looks like every other page on the site. Same theme, same navigation, same search. When the team adds new libraries, the reference updates from the comments in the code, automatically.
The downside is that you have to write the extension if one doesn’t exist for your platform. But that’s a one-time effort, and the alternative is maintaining reference docs by hand and watching them go stale every release.
Why this matters more now
Structured API reference is also exactly what AI agents need to write correct code. When an agent has to know what parameters a function takes, or what its return type is, the reference is more reliable than any tutorial. It comes straight from the source.
Doxygen’s XML already contains all of that. Publishing it properly means it’s useful for both humans and AI, not just one or the other.
So is Doxygen going out of style?
The template is, but the tool isn’t. Doxygen still does the hardest part: extracting structured documentation from code.